
I wanted to create a simple webpage that will help you better understand how UC Berkeley Master of Information Data Science transformed a non-technical student who only knew how to read SQL queries.
To be more specific, this will be a short comprehensive review of my time at UC Berkeley Master of Information and Data Science. Each section is chronologically ordered by the classes that I took and will include samples of codes, screenshots, and links to my work. If any of the links are broken, please let me know at richard.ryu@ischool.berkeley.edu
W200 Python Fundamentals for Data science (2018 Summer)
This was my first “coding” class in an academic setting. Coming in with only 2+ years of SQL and some decent excel skills, there were parts that were easy to understand like If conditions, and different data structures like float vs int. However, what I remember most from this class were two things:
- Great community. Our class was comprised of students with no python background from all ages and all genders. With a common goal of learning, everybody (including the TAs and the instructors) helped each other out and was readily available!
- Like any languages, English, French, Spanish, or Chinese, there’s unbelievable depths and nuisance in Python. To name a quick example, a simple list comprehension can replace a for loop that’s 10+ lines long. Productivity can’t be measured by the volume of code, yet we should try to evaluate the quality of the code that’s being produced.
Highlights
- Object Oriented Programming, Functional Programming
- Learned about Data Structures
- EDA in Python (pandas, numpy, matplotlib)
- Learned how to Git
- Pseudo-coding
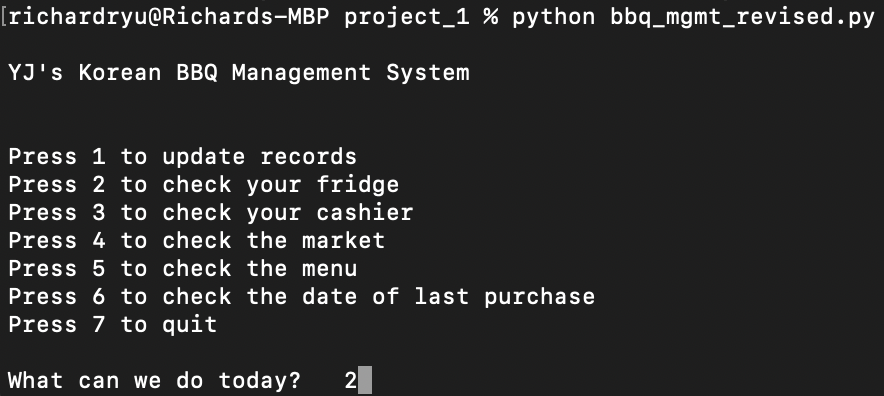
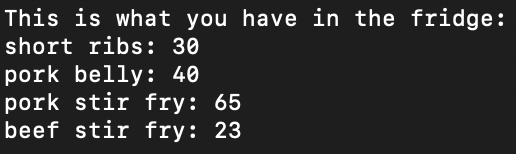
Mid Term Project: BBQ Management System
- First python application I ever wrote! A restaurant management application for my friend’s Korean BBQ restaurant
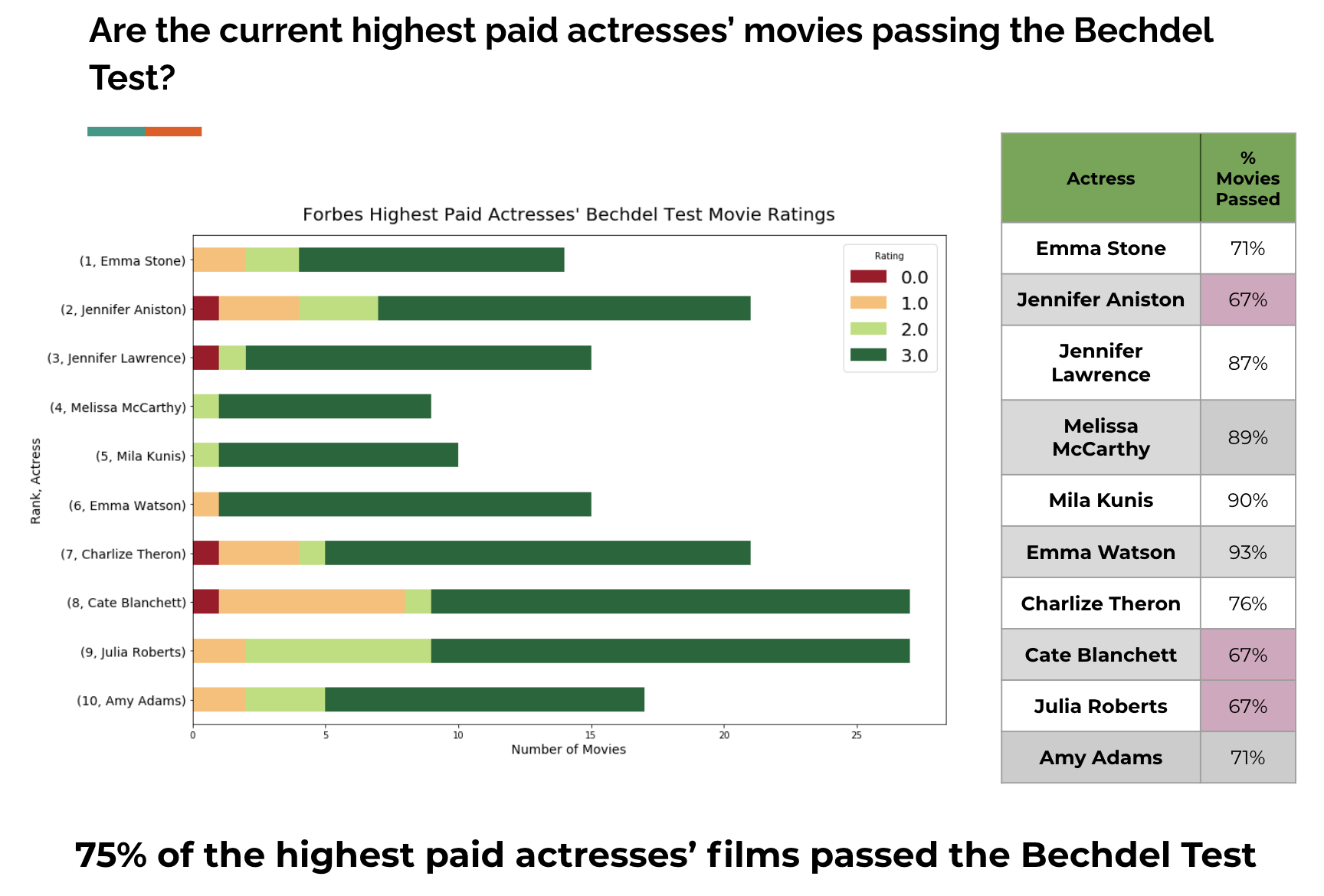
Final Project: Bechdel Analysis
- Used pandas on webscraped data from Box Office Mojo and IMDB

W203 Statistics for Data Science (2019 Summer)
I took a year break after my first semester at UC Berkeley MIDS due to my commitments as a product manager. However, I decided to re-prioritize and return to school full-time by taking Statistics and Data Engineering during the summer of 2019.
Highlights
- Probability Theory and foundational understanding of classical statistics and how it fits within the broader context of data science
- Learned and used R for most assignments
Final Project: Linear Regression on North Carolina Crime data
- Our project group, Significant Effects, consisting of Jeff Li, Vasanth Ramani, and Richard Ryu, has been tasked by an imaginary political campaign in North Carolina to identify determinants of crime
- As a result of our analysis, we came up with 3 different linear regression models to predict crime in North Carolina
- We evaluated the models through: CLM assumptions and fit


W205 Fundamentals of Data Engineering (2019 Summer)
I was always fascinated by the fast moving lines of log on a terminal. I got a chance to watch a lot of that in work, when I participated in a project to switch the host infrastructure of our web platform from AWS to Microsoft Azure. By the time I was done with W205 Data Engineering, I think I have a general idea of what all those fast moving lines of logs were doing.
Highlights
- First introduction to the world of Docker Containers, cloud services (GCP), data pipeline, query, transformation, and streaming
- Learned how to use Kafka, Spark, and Flask
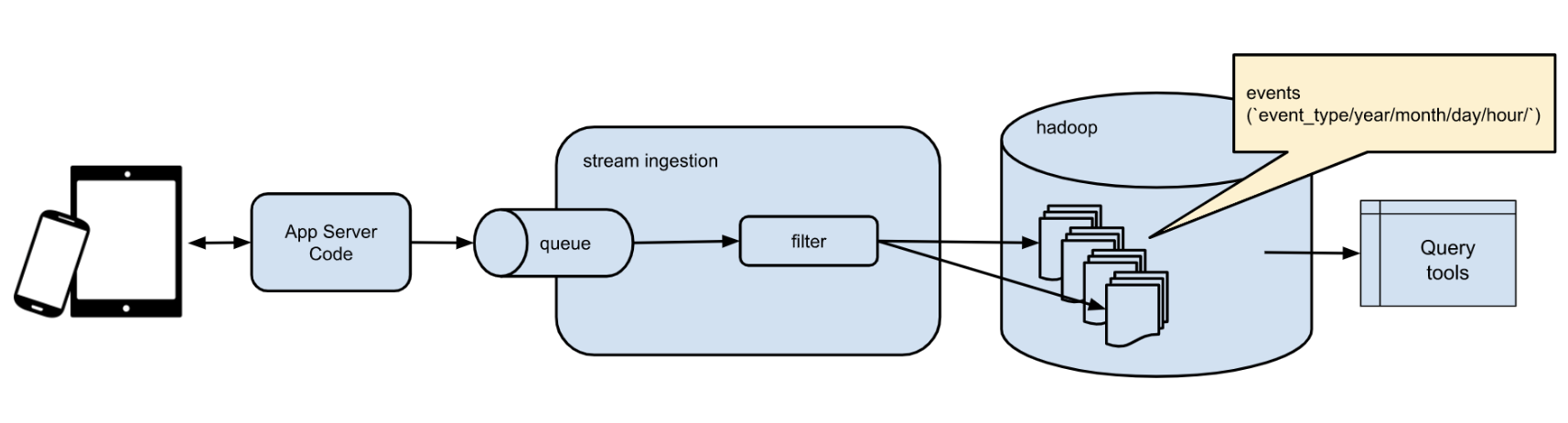
Final Project: Instrument an API server to catch and analyze events for a mobile gaming company
- Each weekly assignments build up to the final project where we put it all together in a single data pipeline. Tools and packages leveraged in the final pipeline:
- Docker Containers
- Kafka
- Flask
- Hadoop HDFS
- PySpark SQL
- Pandas, Jupyter Notebook, Numpy

W209 Data Visualization (2019 Fall)
I was a bit hesitant to take this class since I already had decent business intelligence/data visualization background. I'm proficient with Tableau and have delivered data visualizations to managers of global pharmaceutical companies through SiSense and Microsoft PowerBI. However, this class made me realize that we're all actually spoiled by the data visualization tools out there. A lot of the fundamental concepts/theory behind designing a good data visualization that we learned in this class, is already selected/guided by tools such as Tableau or SiSense. We not only learned the fundamentals of good data visualization, but also learned how to code our own data visualization through D3.js. After all, a picture is worth more than thousand words.
Highlights
- Main exposure to D3.js, with general front-end concepts
- Data visualization concepts, theory, etc.
- A picture is worth more than thousand words
- Tableau
- D3.js examples
Final Project: MOSS Dashboard
- Created a dashboard that will visualize the outcome of LIME
- github
- Final Presentation
W207 Applied Machine Learning (2019 Fall)
This was my official introduction to Machine Learning. Yes, it took only about a year before I actually got the chance to do Machine Learning. I got a chance to learn from Yacov Salomon and one thing I will remember the most is his whiteboard and always dry markers… and how he always emphasized the importance of understanding the intuition behind any algorithms. To get a better understanding of what I mean, take a look at the Q&A below from one of the assignments:
Q: Any ideas why logistic regression doesn't work as well as Naive Bayes?
A: The difference between Naive Bayes and logistic regression is that Naive Bayes assumes independence amongst features while logistic regression looks for relationships between features. Since we're dealing with more than 2,000 features, the logistic regression will perform badly due to complexity. If we want to improve the performance of our logistic regression model, we must reduce the number of features
Highlights
- Heavy Exposure: sklearn, numpy, matplotlib
- Code Sample from one of the Assignments analyzing poisonous mushrooms:
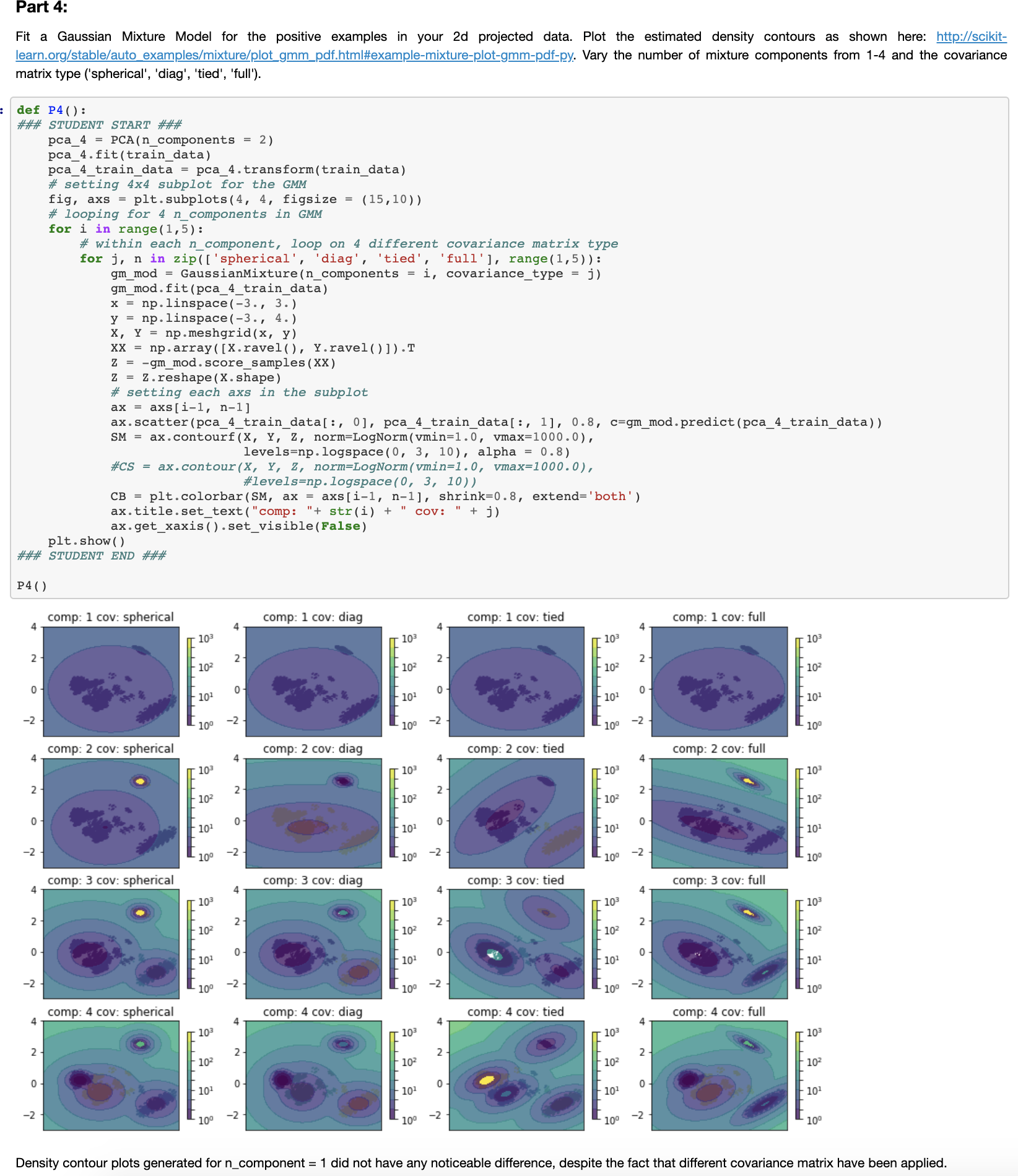
- Thoughts: I think this is the level of technical expectation that's expected from us, about half way into the program. Many differences and improvements can be noticed from my first python code :D. However, I do want to emphasize that my experience at UCB MIDS would not have been possible without all the positive/constructive participation of my fellow classmates, the TAs, and the instructors. Thank you to them.
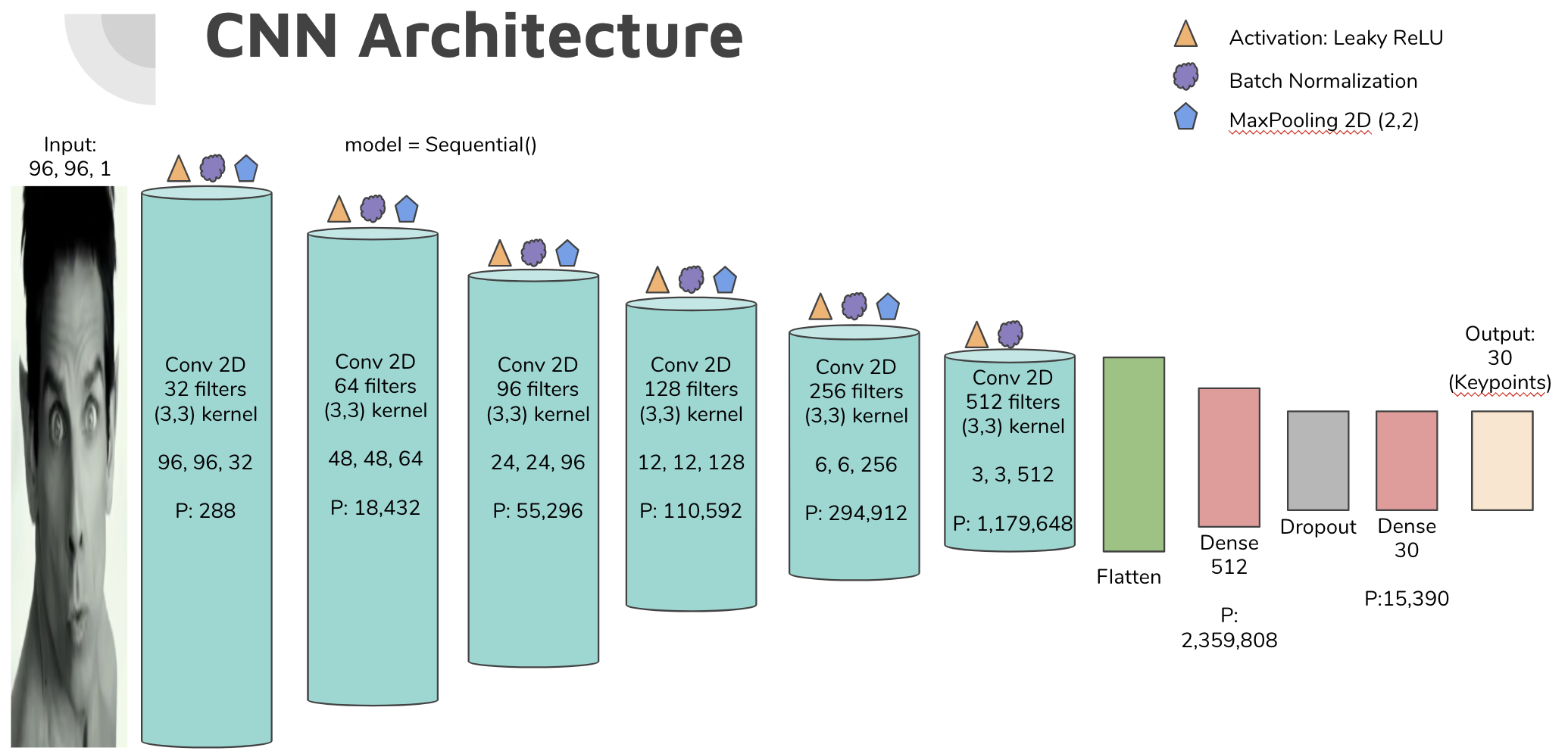
Final Project: Kaggle - Facial Keypoint Detection Challenge
- This was my first Kaggle competition
- Used Keras, tensorflow, skimage, sklearn, pandas, numpy, matplotlib, CUDA, CuDNN
- presentation
- github
- final notebook

W251 Deep Learning in the Cloud at the Edge (2020 Spring)
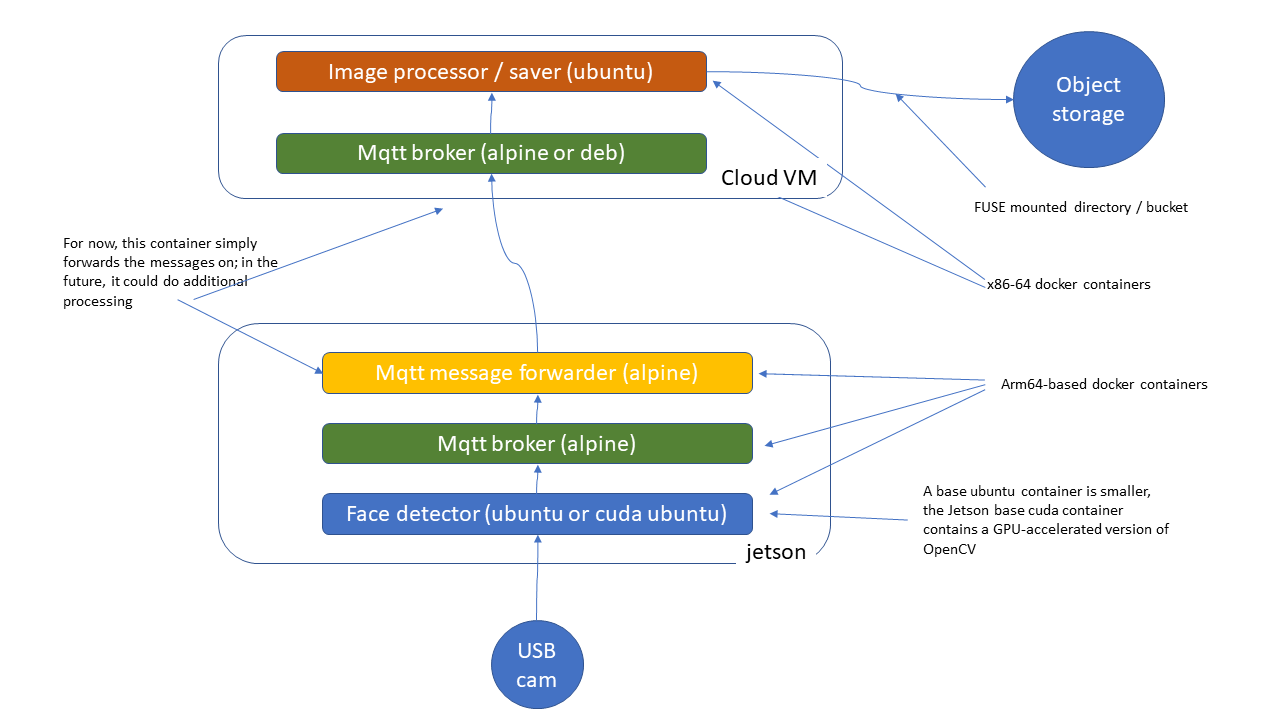
Despite the fact that data is growing at an exponential rate, there are so many un-captured data in the wild. This is where edge computing comes in and what this class is all about. Our first task was to setup a NVIDIA Jetson TX-2 with ubuntu. With the Jetson and IBM Cloud, we got to experiment with various algorithms of Deep Learning and truly appreciate the possibilities of big data.
NOTE: If you're not sure what Jetson TX-2 is, Bin Wang provided a nice video below that basically describes the first week of class for us
Highlights
- Heavy exposure to Docker Containers, IBM cloud, dev/ops, IoT, edge computing, deep learning, NVDIA Jetson TX-2
- Tuning models to safely land a lunar lander on moon github

- Trained a Transformer-based Machine Translation Network on a small English to German WMT corpus github
- Capture facial images from a webcam that is attached to the Jetson TX-2. Then, send the captured facial images to the cloud object storage on IBM virtual servers using MQTT github
Final Project: Kaggle - Deep Fake Detection Challenge
- Participated in the Deepfake Detection Challenge to predict whether or not a particular video is a deep fake
- Used IBM Cloud for the pipeline
- Leveraged MTCNN, mixnet_m, LSTM, PyTorch, CUDA 10.0 for training
- Achieved an accuracy of ~ 88.81% and log loss of 0.25, when predicting videos with a single face captured
- github
- presentation

Below is an example of a real video
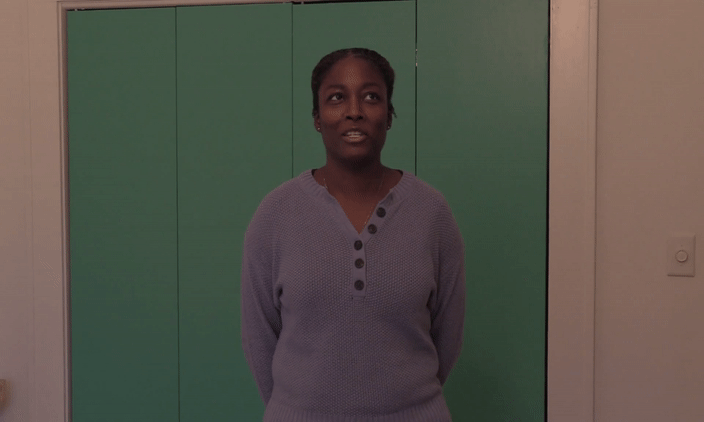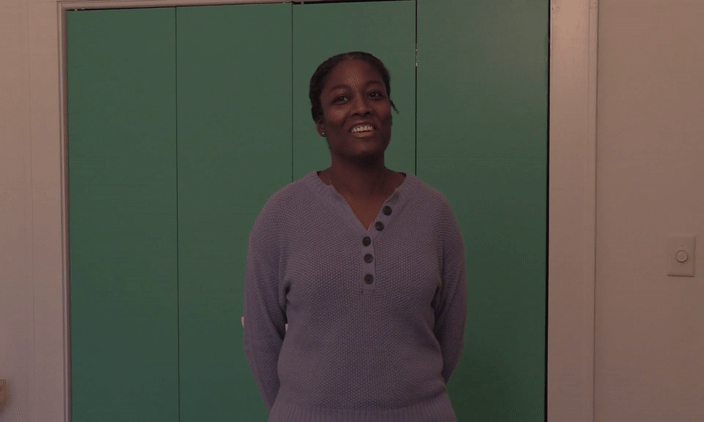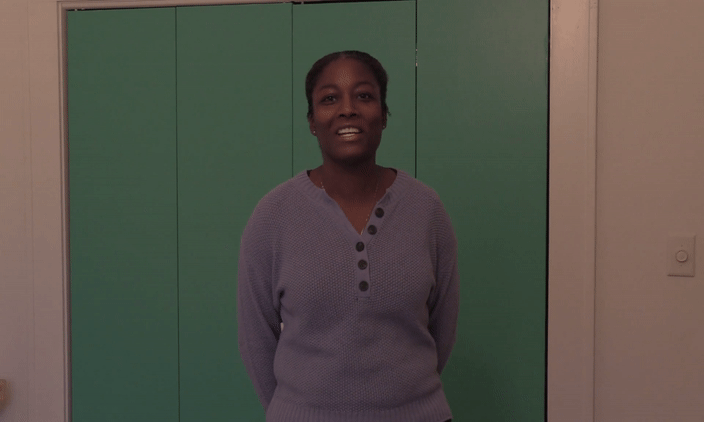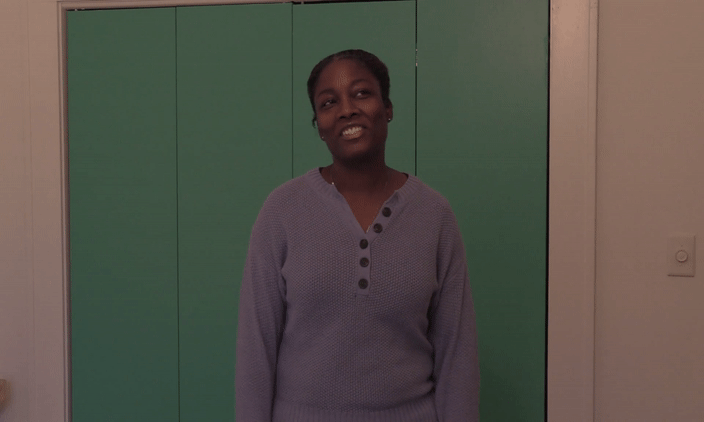
Below is an example of a fake video

Can you tell the difference? :)
W261 Machine Learning at Scale (2020 Spring)
This course teaches the underlying principles required to develop scalabe machine learning pipelines for structured and unstructured data at the petabyte scale. Students will gain hands-on experience in Apache Hadoop and Apache Spark.
Highlights
- Learn to recognize and apply key concepts in parallel computation and MapReduce design
- Design stateless parallelizable implementations of core machine learning algorithms from scratch
- Gain hands-on experience using Apache Hadoop and Apache Spark to analyze large datasets
- OLS, Ridge, and Lasso with Spark RDDs
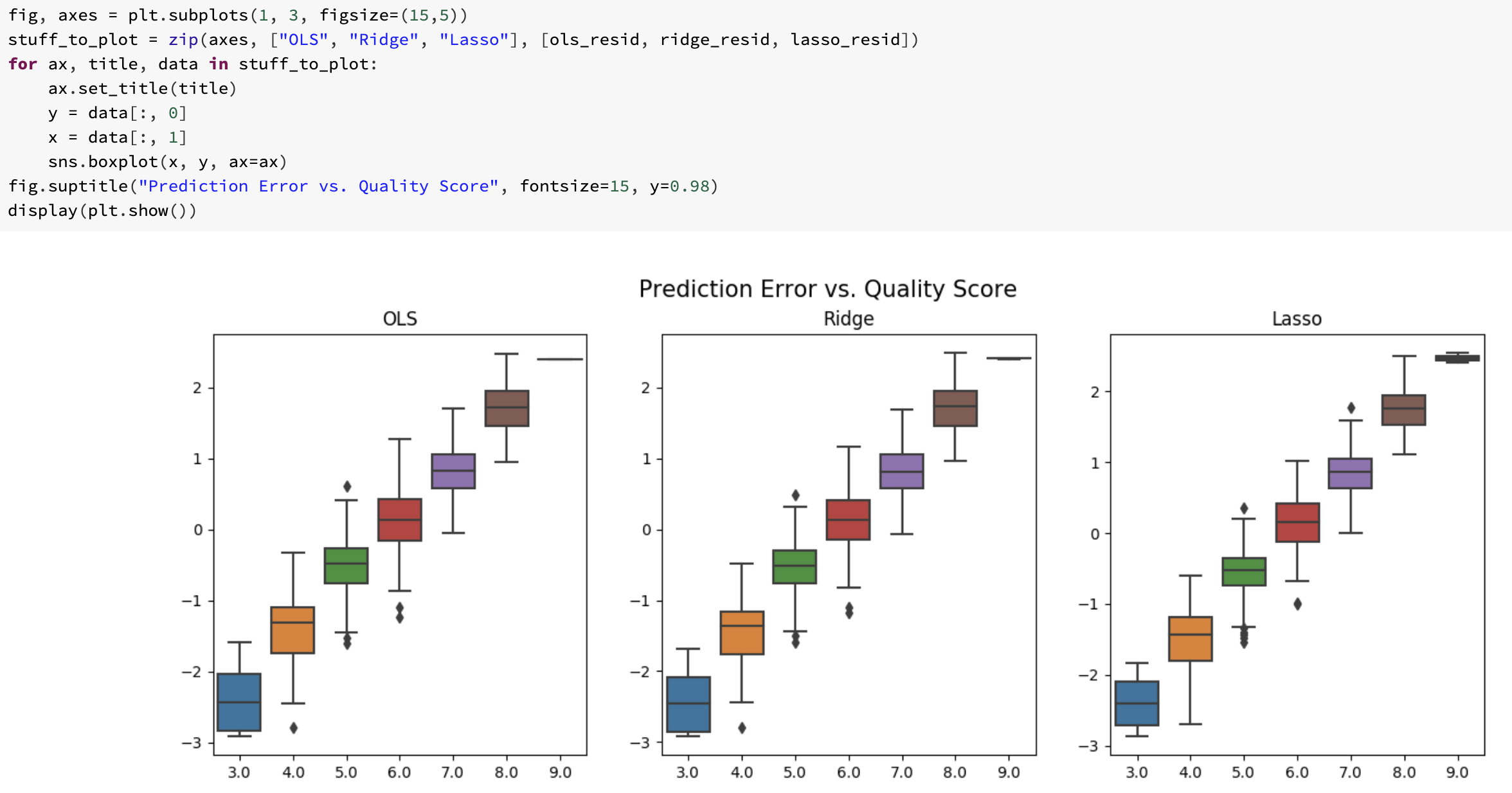
Final Project: Predict Flight Delay at Scale
Can weather data and basic airline metadata be used to predict whether or not a given flight will be delayed at a level of accuracy that will be practically useful? We used 'PySpark.ml.feature VectorAssembler' to prepare feature engineered data for Linear Regression and Gradient Boosted Decision Tree models. Although the results were not promising (RMSE ~42.15 and ~78.2% accuracy) for our final model, it was a good data science experience with my teammates Andrew Webb, Suzy Choi, and Pierce Coggins. To be specific, we got to experience the process of preparing our own data from scratch for the analysis and the invaluable experience of explaining why it wasn't effective. (This is the hard part!)

W210 Capstone (2020 Summer)
This is it. I teamed up with Hong, Michelle, and Rachael to come up with AccessiPark Denver
Our Plan:
- First, train a model to detect street-level accessibility obstacles like lamps, fire hydrants, no parking signs
- Second, Find areas from a zipcode level with the total count of accessibility parking signs
- Third, use feature engineering, googlemaps, and data visualization to disseminate this information
Highlights
- Train YOLOv5 on custom labelled images via Google Colab
- Used Googlemaps reverse_geocode
# You will need an active googlemaps API code
# david = pd.DataFrame(columns=['new_lat', 'new_long'])
import googlemaps
gmaps = googlemaps.Client(key = 'your API key')
for i in list(range(len(david))):
temp_result = gmaps.reverse_geocode((david.loc[i,'new_lat'], david.loc[i, 'new_long']), result_type = "postal_code")
david.loc[i, 'zipcode'] = temp_result[0].get('address_components')[0].get('long_name')
- For more details and code samples of all the feature engineering required for this project, please refer to the README.md on our project github